|
Внутримашинное информационное обеспечение
Варианты организации
внутримашинного информационного обеспечения
Внутримашинное информационное обеспечение связано с хранением,
поиском и обработкой информации и состоит из разнообразных по содержанию,
назначению, организации файлов и информационных связей между ними. Оно включает
все виды специально организованной на машинных носителях информации для
восприятия, передачи и обработки техническими средствами. Внутримашинное ИО
может быть создано либо как множество локальных (независимых) файлов, каждый из
которых отражает некоторое множество однородных управленческих документов
(например, «Ведомость подетальных норм расхода материалов в натуральном и
стоимостном выражении», «Применяемость деталей в изделии»), либо как база
данных. При создании базы данных файлы не являются независимыми, ибо структура одних
файлов (состав полей) зависит от структуры других. Поэтому структура файлов
базы данных часто не соответствует структуре управленческих документов, на
основе которых эти файлы создаются. Файлы БД разрабатываются с соблюдением
определенных принципов и ориентацией на одну из моделей базы данных
(иерархическую, сетевую, реляционную). По содержанию внутримашинное ИО должно
адекватно отражать реальную действительность организационного объекта и его
подразделений, т. е. конкретную предметную область.
Файлы внутримашинной базы делятся на переменные, в которых
отражаются факты финансово-хозяйственной деятельности объекта управления, и
условно-постоянные, в которых представлены материальные, трудовые,
технологические и другие нормы и нормативы, а также справочные данные.
Выходные файлы предназначены для формирования отчетности,
использования их информационной системой при решении других задач и при решении
задач в последующий период. Кроме того, существуют вспомогательные,
корректировочные и рабочие файлы, которые уничтожаются после каждого решения
задачи.
Внутримашинное информационное обеспечение предназначено для
быстрого и удобного удовлетворения информационных потребностей всех
пользователей информационных технологий.
При выборе рационального варианта организации внутримашинного
информационного обеспечения, наиболее полно отражающего специфику объекта
управления, к нему предъявляют следующие требования: полнота представления
данных; минимальность состава данных; минимизация времени выборки данных при
решении задач управления; независимость структуры массивов от программных
средств их организации; динамичность структуры информационной базы.
Организация, состав, структура внутримашинного информационного
обеспечения зависят от информационных характеристик предприятия, состава
решаемых задач, методов их решения, возможностей программных средств,
организации массивов (файлов), используемых технических средств.
Данные во внутримашинном ИО могут храниться, как известно, двумя
способами — непосредственно в виде файлов или в базе данных. Новые
информационные технологии требуют интеграции информационных процессов и, в
частности, организации информации в виде совокупности баз данных.
Организация информационной базы на основе концепции баз данных
позволяет обеспечить многоаспектный доступ к совокупности взаимосвязанных
данных, интеграцию и централизацию управления данными, устранение излишней
избыточности данных, возможность совмещения эффективных режимов пакетной и
диалоговой обработки данных.
Информационная база, организованная на основе локальных файлов,
состоит из совокупности массивов, предназначенных для решения отдельных задач.
Для каждой задачи необходимая информация складывается из следующих
составляющих: множества входных переменных массивов; множества массивов, получаемых
в результате решения других задач; множества массивов, получаемых от
предыдущего решения данной задачи; множества массивов нормативно-справочной
информации; множества процедур обработки данных; множества массивов, хранимых
для последующего решения данной задачи; множества массивов, хранимых для
решения других задач; множества выходных документов.
При этом основным недостатком информационной базы является не
только обилие массивов и их связей, но и то, что она не обеспечивает
независимости программ решения задач от структур обрабатываемых данных. Любое
изменение структуры входных массивов вызывает необходимость изменения программ,
а это в свою очередь приводит к большим затратам на поддержание информационной
базы. Кроме того, при такой организации информационная база несет в себе
значительную долю избыточности из-за повторения одних и тех же реквизитов в
разных массивах, ориентированных на решение локальных задач и практически не
связанных между собой. Банк данных, его состав, модели
баз данных
При увеличении объемов информации для многоцелевого применения и
эффективного удовлетворения информационных потребностей различных пользователей
используется интегрированный подход к созданию внутримашинного ИО. При этом
данные рассматриваются как информационные ресурсы для разноаспектного и
многократного использования. Принцип интеграции предполагает организацию
хранения информации в виде банка данных (БнД), где все данные собраны в едином
интегрированном хранилище и к информации как важнейшему ресурсу обеспечен
широкий доступ различных пользователей.
Таким образом, банк данных (БнД) — это система
специальным образом организованных данных (баз данных), программных,
технических, языковых, организационно-методических средств, предназначенных для
обеспечения централизованного накопления и коллективного многоцелевого
использования данных.
Основные требования к БнД включают: интегрированность баз данных и
целостность каждой из них; независимость, минимальную избыточность хранимых
данных и способность к расширению. Важным условием эффективного
функционирования БнД является обеспечение защиты данных от несанкционированного
доступа или случайного уничтожения хранимых данных.
Любой банк данных в своем составе всегда содержит следующие два
основных компонента: базу данных (БД), которая есть не что иное, как
даталогическое представление информационной модели предприятия, и систему
управления базой данных (СУБД), с помощью которой реализуются централизованное
управление данными, хранимыми в базе, доступ к ним и поддержание их в
состоянии, соответствующем состоянию предметной области.
Базы данных создаются в БнД предприятия для решения на ПК задач
управления производством.
Для программной реализации работ с БД создаются вспомогательные
программы их структур, справочников и файлов, печати и др.
Центральную роль в функционировании банка данных выполняет система
управления базой данных (СУБД). СУБД — это пакет
программ, обеспечивающий поиск, хранение, корректировку данных, формирование
ответов на запросы. Система обеспечивает сохранность данных, их
конфиденциальность, перемещение и связь с другими программными средствами.
Основные функции СУБД: непосредственное управление данными во внешней памяти;
управление буферами оперативной памяти; управление транзакциями; журнализация;
языки БД.
Организация типичной СУБД и состав ее компонентов соответствует
рассмотренному набору функций. Логически в современной реляционной СУБД можно
выделить наиболее внутреннюю часть -ядро СУБД, компилятор языка БД (обычно SQL), подсистему поддержки времени выполнения, набор утилит.
Преимущества работы с БнД для пользователей окупают затраты и
издержки на его создание. Они заключаются в следующем: повышается
производительность работы пользователей, достигается эффективное удовлетворение
информационных потребностей; централизованное управление данными освобождает
прикладных программистов от организации данных, обеспечивает независимость
прикладных программ от данных; организация банка (базы) данных позволяет
реализовать другие нерегламентированные запросы, приложения; снижаются затраты
не только на создание и хранение данных, но и на поддержание их в актуальном
динамичном состоянии; уменьшаются потоки данных, циркулирующих в системе,
сокращается избыточность и дублирование.
Концепция банка данных — это не только идея интегрированного
хранения данных, но и идея отделения описания данных от программ их обработки,
интерфейс между которыми обеспечивается системой управления базами данных
(СУБД). В основу ее разработки закладывают следующие принципы: единство структурно-информационной
организации массивов; централизацию процессов накопления, хранения и обработки
различных видов информации; однократный ввод первичных массивов информации с
последующим многоразовым и многоцелевым их использованием; интегрированное использование
массивов в различных режимах обработки; оперативность доступа к различным
элементам информационных массивов; минимизацию стоимости создания и
функционирования.
По организации и технологии обработки данных базы данных
подразделяются на централизованные и распределенные.
Централизованную базу данных отличает традиционная
архитектура баз данных (рис. 3.3).
При подобной архитектуре все необходимые для работы специалистов
данные и СУБД размещены на центральном компьютере, или мэйнфрейме (mainframe), вместе с приложением, принимающим входную
информацию с пользовательского терминала и отображающим данные на экране
пользователя. Предположим, что пользователь вводит запрос, требующий
последовательного просмотра базы данных (например, запрос на расчет потребности
материалов на деталь в натуральном и стоимостном выражении). СУБД получает этот
запрос, просматривает БД, выбирая с диска нужную запись, вычисляет значение и
отображает результат на экране. Приложение и СУБД работают на одном компьютере,
и, поскольку система обслуживает много различных пользователей, каждый из них
ощущает снижение быстродействия по мере увеличения нагрузки на систему. 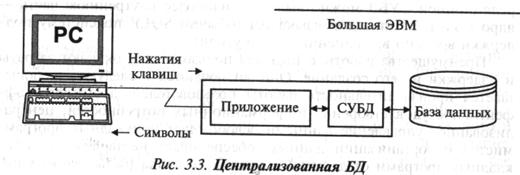
Распределенная база данных состоит из нескольких, возможно
пересекающихся или даже дублирующих друг друга частей, хранимых в различных
компьютерах вычислительной сети. Работа с такой БД осуществляется с помощью
системы управления распределенной базой данных (СУРБД).
По способу доступа к данным БД разделяются на БД с локальным
доступом и БД с удаленным (сетевым) доступом.
Системы централизованных БД с сетевым доступом предполагают
различные архитектуры подобных систем: файл-сервер и клиент-сервер.
Появление персональных компьютеров и локальных вычислительных сетей
привело к разработке архитектуры «файл-сервер», показанной на рис. 3.4. При
такой архитектуре приложение, выполняемое на ПК, может получить прозрачный
доступ к файл-серверу,
на котором хранятся совместно используемые файлы. Когда приложению,
работающему на ПК, требуется получить данные из совместно используемого файла,
сетевое программное обеспечение автоматически считывает требуемый блок данных с
сервера. Наиболее популярные БД для ПК, включая Microsoft Access, Paradox
и dBase, поддерживают архитектуру «файл-сервер», при
которой на каждом ПК работает своя копия СУБД.
При выполнении обычных запросов эта архитектура обеспечивает
великолепную производительность, поскольку в распоряжении каждой копии СУБД
находятся все ресурсы ПК. Однако рассмотрим приведенный выше пример. Поскольку
запрос требует последовательного просмотра БД, СУБД постоянно запрашивает все
новые блоки данных из БД, которая физически расположена на сервере сети.
Очевидно, что в результате СУБД запросит и получит по сети все блоки файла. При
выполнении запросов такого типа эта архитектура создает слишком большую
нагрузку на сеть и уменьшает производительность работы. 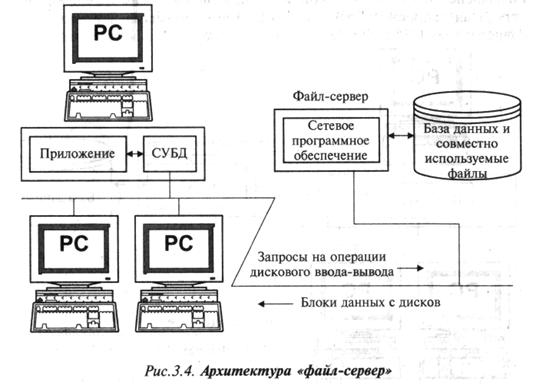
Архитектура «клиент-сервер» показана на рис. 3.5. При такой
архитектуре ПК объединены в локальную сеть, в которой имеется сервер баз
данных, содержащий общие БД. Функции СУБД разделены на две части.
Пользовательские программы, такие, как приложения, для формирования
интерактивных запросов и генераторы отчетов, работают на клиентском компьютере.
Хранение данных и управление ими обеспечиваются сервером. В этой архитектуре SQL стал стандартным языком, предназначенным для обработки и
чтения данных, содержащихся в БД. SQL обеспечивает
взаимодействие между пользовательскими программами и ядром БД.
Вернемся к примеру определения потребности материалов на деталь.
При архитектуре «клиент-сервер» запрос передается по сети на сервер БД в виде SQL-запроса. Ядро БД на сервере обрабатывает запрос и
просматривает БД, которая также расположена на сервере. После вычисления
результата ядро БД посылает его обратно по клиентскому приложению, которое
отображает его на экране ПК. Архитектура «клиент-сервер» позволяет сократить
трафик и распределить процесс загрузки базы данных. Функции работы с
пользователем, такие, как обработка ввода и отображение данных, выполняются на
ПК пользователя. Функции работы с данными, такие, как дисковый ввод-вывод и
выполнение запросов, выполняются сервером БД. Наиболее важно здесь то, что SQL обеспечивает четко определенный интерфейс между
клиентской и серверной системами, эффективно передавая запросы на доступ к БД.
Эта архитектура используется в современных СУБД Oracle,
Informix, Sybase и до.
С ростом популярности СУБД появилось множество различных моделей
данных. У каждой из них имелись свои достоинства и недостатки, которые сыграли
ключевую роль в развитии реляционной модели данных, появившейся во многом
благодаря стремлению упростить проектирование, упорядочить работу с моделями
данных и повысить ее эффективность.
Основным средством организации и автоматизации работы с БД являются
системы управления базами данных (СУБД).
Выбор СУБД определяется многими факторами, но главным из них
является возможность работы с конкретной моделью данных (иерархической,
сетевой, реляционной).
Иерархическую модель БД изображают в виде дерева (рис. 3.6).
Элементы дерева вершины 1—14 представляют совокупность данных, например
логические записи. Каждой вершине соответствует множество экземпляров записей,
составляющих логический файл. Вершины расположены по уровням и связаны между
собой отношениями подчиненности. Одна-единственная вершина верхнего уровня
является корневой. Иерархическая модель данных обеспечивает так называемые
одно-многозначные отношения между данными. Примером таких отношений могут
служить следующие: одному изделию соответствует несколько материалов,
используемых на различных операциях обработки, сборки. 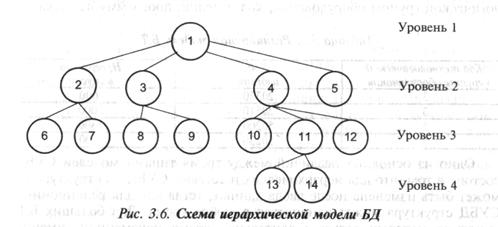
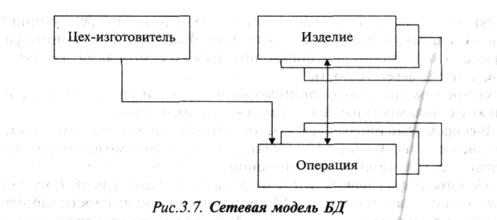
Сетевые модели БД соответствуют более широкому классу объектов
управления, хотя требуют для своей организации и дополнительных затрат. Сетевая
модель позволяет любому объекту быть связанным с любым другим объектом. Сетевые
модели сложны, что создает определенные трудности при необходимости
модернизации или развития СУБД. Пример сетевой модели БД представлен на рис.
3.7. На рисунке видно, что одно изделие изготавливается в результате выполнения
нескольких операций, а одна операция может использоваться для изготовления
различных изделий.
Реляционная модель БД представляет объекты и
взаимосвязи между ними в виде таблиц, а все операции над данными сводятся к
операциям над этими таблицами. На этой модели базируются практически все современные
СУБД. Эта модель более понятна, «прозрачна» для конечного пользователя
организации данных. К преимуществам реляционной модели БД можно отнести также
более высокую гибкость при расширении БД, состава запросов к ней. Реляционная
организация БД в виде таблицы содержит программу выпуска изделий (табл. 3.5).
Эта база данных включает в себя три атрибута: код технологической группы
оборудования, код изделия, программу выпуска.
Далее |

